第二部分:实践篇
2.1 快速入门:YOLOv11s 模型转换
本章以 YOLOv11s 模型为例,通过一个完整的端到端示例,带您体验使用 taNNTC 工具链完成模型导入、量化与导出的全过程。
2.1.1 前期准备
-
模型下载
-
量化校准数据集下载
解压后将图片存放至指定目录,用于量化校准。
-
配置文件下载
2.1.2 组织目录结构
在进行模型编译与量化前,建议按如下目录组织文件,便于工具链调用与管理:
project_yolo11s/
├── dataset.txt # 量化数据集列表文件
├── yolo11s_config.json # 工具链配置文件
├── yolo11s.onnx # 源 ONNX 模型文件
└── val2017_1000/ # 量化校准数据集
├── 0000000000.jpg
├── 0000000001.jpg
├── 0000000002.jpg
└── ...
说明:taNNTC 支持通过文本配置文件指定模型的输入和输出节点。如果不进行配置,系统将自动识别模型的 I/O 节点(适用于默认全模型量化)。以 YOLOv11s 为例:
-
输入节点
- images
-
输出节点
- /model.23/Reshape_output_0
- /model.23/Reshape_1_output_0
- /model.23/Reshape_2_output_0
2.1.3 输出说明
YOLOv11s 的三个输出对应三个不同尺度的特征图(stride = 8、16、32)。 每个预测点都会输出一个 144 维向量,其中包含边界框和分类信息。
- 144 维向量的组成:
- 前 64 维:边界框回归信息(采用 DFL 分布形式,对
x、y、w、h各 16 个 bin 编码)。 - 后 80 维:类别置信度(每个通道对应一个类别,已融合 objectness 概念)。
- 前 64 维:边界框回归信息(采用 DFL 分布形式,对
- 第三维度(6400 / 1600 / 400):表示该尺度下的网格点数
[1,144,6400]→ 对应 80×80 特征图(小目标)[1,144,1600]→ 对应 40×40 特征图(中目标)[1,144,400]→ 对应 20×20 特征图(大目标)
量化数据集:工具链支持以文本格式指定量化数据集路径文件 dataset.txt,文件格式如下:
val2017_1000/0000000000.jpg
val2017_1000/0000000001.jpg
val2017_1000/0000000002.jpg
...
- 每行对应一张图片的相对路径或绝对路径。
- 建议数据集涵盖多种场景、光照和角度,以提升量化精度。
- 数据集规模通常建议在 100~1000 张之间,根据模型大小和精度需求调整。
下载的 config_file 目录下包含一个示例配置文件 dataset.txt,可以直接使用。
2.1.4 模型编译与量化
进入 project_yolo11s/ 目录,打开 yolo11s_config.json 文件,进行工具链配置。
- 生成 FP16 模型
在 yolo11s_config.json 文件中找到 quantize 段,修改如下:
"quantize": {
"qtype": "float16",
"dataset_file_type": "TEXT",
"dataset_file": "./dataset.txt"
},
- 生成 INT8 模型
在 yolo11s_config.json 文件中找到 quantize 段,修改如下:
"quantize": {
"qtype": "int8",
"dataset_file_type": "TEXT",
"dataset_file": "./dataset.txt",
"input_num": 25
},
执行下列命令生成可在 EA65 系列 NPU 上运行的 .nb 格式模型。
convert_model build --config yolo11s_config.json
执行成功后,最终用于板端部署的文件将位于 output/ 目录下,名为 yolo11s_int8.nb。
2.1.5 工具解析:从示例到实践
我们提供的 convert_model 工具是实现模型一键式编译与量化的便捷工具,需要配合 JSON 配置文件使用。为了帮助您更好地理解其工作原理,并能根据自身需求进行灵活配置,本节将对 convert_model 工具的核心命令进行分步解析。
因此,您可以将此 sample 视为一个最佳实践模板。配置文件中的每一个字段都由一系列参数构成,这些参数的具体含义和更多用法,均可在 「TacoAI NN 工具链技术手册」文档的「参数篇」章节 中查阅。
convert_model 工具的核心流程主要分为三个阶段:模型导入、生成配置文件、模型量化和模型导出。
阶段一:模型导入 (Import)
将 ONNX 模型转换为 taNNTC 的中间表示 (IR)。
// .json 中的参数
"import" : {
"name": "yolo11s",
"framework": "ONNX",
"onnx_model": "./yolo11s.onnx",
"inputs": "images",
"outputs": "/model.23/Reshape_output_0 /model.23/Reshape_1_output_0 /model.23/Reshape_2_output_0",
"input-size-list": "1,3,640,640"
},
- 关键参数说明:
framework:指定当前执行的是 "ONNX 模型导入" 任务。onnx_model:指定输入的源 ONNX 模型文件路径。inputs: ONNX 模型文件的输入名outputs: ONNX 模型文件的输出名input-size-list:ONNX 模型文件的输入 tensor shape
阶段二:生成配置文件 (Generate)
此步骤基于导入后的模型结构,生成预处理和后处理的 .yml 配置文件模板。
// 1. 生成输入端预处理配置
"preprocess": [{
"reverse_channel": false,
"mean": [0, 0, 0],
"std": [1.0, 1.0, 1.0],
"scale": 0.00392156,
"add_preprocess_node": false
}
],
// 2. 生成输出端后处理配置
"postprocess": [
{
"add_postprocess_node": false,
"permute": [0,1,2,3],
"float32_out": false
},
{
"add_postprocess_node": false,
"permute": [0,1,2,3],
"float32_out": false
},
{
"add_postprocess_node": false,
"permute": [0,1,2,3],
"float32_out": false
}
],
📝 说明:
- 默认生成的
.yml文件包含默认参数,需要根据模型需求进行修改。
针对 YOLOv11s 这个模型来说,此处完成了两个关键修改:
// 将 reverse_channel 从 true 修改为 false
"reverse_channel": false,
// 将 scale 值从 1.0 修改为 1/255 (0.003921569)
"scale": 0.00392156,
- 关闭通道反转:因为 YOLOv11s 模型训练时使用的就是 RGB 格式的输入。
- 设置归一化系数:将输入图像的像素值从
[0, 255]范围归一化到[0, 1]范围。
对于您自己的模型,您需要根据实际的预处理逻辑,手动或通过脚本修改这一部分。
阶段三:模型量化 (Quantize)
利用校准数据集生成量化参数。
"quantize": {
"qtype": "int8",
"dataset_file_type": "TEXT",
"dataset_file": "./dataset.txt",
"input_num": 25
},
- 命令解析:
qtype:定义量化目标数据类型(int8)。dataset_file:数据集文件的路径(此处使用TEXT格式,.txt 文件中是数据的路径)。input_num:指定用于量化的数据数量。
阶段四:模型导出 (Export)
最后一步,将量化后的模型编译并打包成 NPU 可直接加载执行的二进制文件 (.nb)。
"export": {
"core_number": 1
}
- 命令解析:
core_number: 依据本次脚本导出来的模型为单 core 模型。
通过以上解析,可以看到,一个完整的模型部署流程是如何通过组合各阶段的参数来实现。当需要处理自己的模型时,可以以此脚本为基础,参考 「TacoAI NN 工具链技术手册」文档的「第三部分:参数篇」章节 的内容,调整各项参数,以满足特定需求。
2.2 高级专题:混合量化(Hybrid Quantization)
2.2.1 概述与原理
混合量化是一种在精度和性能之间取得更优平衡的策略。其核心思想是:对模型中大部分层使用 INT8/UINT8 高性能定点量化,同时对少数对精度非常敏感的层保留 FP16 半精度浮点计算,从而在保持高精度的同时获得显著的性能提升。
- INT8 量化:将权重和激活映射到 8 位整数,运算效率高,模型体积小,但量化误差可能导致精度下降。
- FP16 保留:对于量化敏感的层(如首尾卷积层、特征融合层等),直接使用 FP16 存储和计算,减少精度损失。
- 混合调度:在推理引擎中,INT8 与 FP16 层可以混合执行,由硬件调度自动完成数据格式的转换与传递。
2.2.2 混合量化流程
在 output/acuity_temp/ 目录下找到模型的中间文件:
tree
.
├── model.data # 模型权重文件
├── model_inputmeta.yml # 模型前处理配置文件
├── model_int8.quantize # 模型量化文件
├── model.json # 模型结构文件
└── model_postprocess_file.yml # 模型后处理文件
可将他们更名为 yolo11s_*, 后续所有操作均使用更名后的文件,具体更名清单如下:
tree
.
├── yolo11s.data # 模型权重文件
├── yolo11s_inputmeta.yml # 模型前处理配置文件
├── yolo11s_int8.quantize # 模型量化文件
├── yolo11s.json # 模型结构文件
└── yolo11s_postprocess_file.yml # 模型后处理文件
步骤 1:搜索敏感层
通过在量化命令中加入特定参数,可以分析每一层在量化过程中的精度损失(熵值),使用下面的命令生成 entropy.txt :
pegasus quantize \
--model yolo11s.json \
--model-data yolo11s.data \
--model-quantize yolo11s_int8.quantize \
--quantizer asymmetric_affine \
--qtype 'int8' \
--with-input-meta yolo11s_inputmeta.yml \
--rebuild \
--compute-entropy
该命令执行后,会生成模型的量化结果文件 yolo11s_int8.quantize (记录每一层的量化参数)以及熵值文件 entropy.txt。熵值取 0~1 之间,数值越接近 1 表示该层量化精度越低,也即损失越大。
.quantize 文件中的末尾 customized_quantize_layers 字段,是推荐进行混合量化的层。你可以不做修改进行混合量化,也可按照步骤2的流程手动配置。
步骤 2:手动配置高精度层 (可选)
根据 entropy.txt 的分析结果,打开 .quantize 配置文件(如 yolo11s_int8.quantize),找到 customized_quantize_layers 字段,将熵值较高的敏感层(例如 > 0.6)添加进去,并指定其使用高精度格式。这里我们以 yolo11s 为例,手动配置混合量化层:
打开 yolo11s_int8.quantize 文件,找到 customized_quantize_layers 字段,将 entropy.txt 中熵值大于 0.6 的层添加到该字段中,如:
model.23/cv3.2/cv3.2.0/cv3.2.0.1/conv/Conv_output_0_59: dynamic_fixed_point-i16
model.23/cv3.1/cv3.1.0/cv3.1.0.1/conv/Conv_output_0_63: dynamic_fixed_point-i16
model.2/m.0/cv1/conv/Conv_output_0_230: dynamic_fixed_point-i16
model.0/conv/Conv_output_0_265: dynamic_fixed_point-i16
model.23/cv3.1/cv3.1.1/cv3.1.1.0/conv/Conv_output_0_51: dynamic_fixed_point-i16
model.23/cv2.2/cv2.2.0/conv/Conv_output_0_45: dynamic_fixed_point-i16
model.23/cv2.1/cv2.1.0/conv/Conv_output_0_49: dynamic_fixed_point-i16
model.1/conv/Conv_output_0_259: dynamic_fixed_point-i16
model.23/cv3.0/cv3.0.1/cv3.0.1.0/conv/Conv_output_0_55: dynamic_fixed_point-i16
model.2/cv1/conv/Conv_output_0_247: dynamic_fixed_point-i16
model.23/cv2.0/cv2.0.2/Conv_output_0_13: dynamic_fixed_point-i16
model.23/cv2.1/cv2.1.2/Conv_output_0_11: dynamic_fixed_point-i16
model.23/cv2.0/cv2.0.1/conv/Conv_output_0_29: dynamic_fixed_point-i16
model.10/m/m.0/attn/pe/conv/Conv_output_0_176: dynamic_fixed_point-i16
model.23/cv2.2/cv2.2.2/Conv_output_0_9: dynamic_fixed_point-i16
model.23/cv2.1/cv2.1.1/conv/Conv_output_0_25: dynamic_fixed_point-i16
model.23/cv2.2/cv2.2.1/conv/Conv_output_0_21: dynamic_fixed_point-i16
做上述修改的时候,由于 .quantize 文件将按照 yaml 格式解析,注意缩进。
步骤 3:执行混合量化并导出
首先,使用 --hybrid 标记执行量化,生成混合量化配置。
pegasus quantize \
--model yolo11s.json \
--model-data yolo11s.data \
--quantizer asymmetric_affine \
--qtype 'int8' \
--with-input-meta yolo11s_inputmeta.yml \
--model-quantize yolo11s_int8.quantize \
--hybrid
这会生成一个新的 yolo11s_int8.quantize.json 文件。然后,使用这个新文件作为 --model 参数来导出最终的混合量化模型。
pegasus export ovxlib \
--model yolo11s_int8.quantize.json \
--model-data yolo11s.data \
--dtype quantized \
--model-quantize yolo11s_int8.quantize \
--target-ide-project 'linux64' \
--with-input-meta yolo11s_inputmeta.yml \
--postprocess-file yolo11s_postprocess_file.yml \
--output-path export/yolo11s_hybrid \
--pack-nbg-unify \
--viv-sdk '/usr/src/vSimulator/x86_64_linux' \
--optimize VIP9200O_PID0X10000049
2.2.3 精度与性能分析
-
精度测算:可根据 Model Zoo 中提供的标准方式进行精度测试,对比混合量化模型与原模型的差异。
-
精度问题排查:
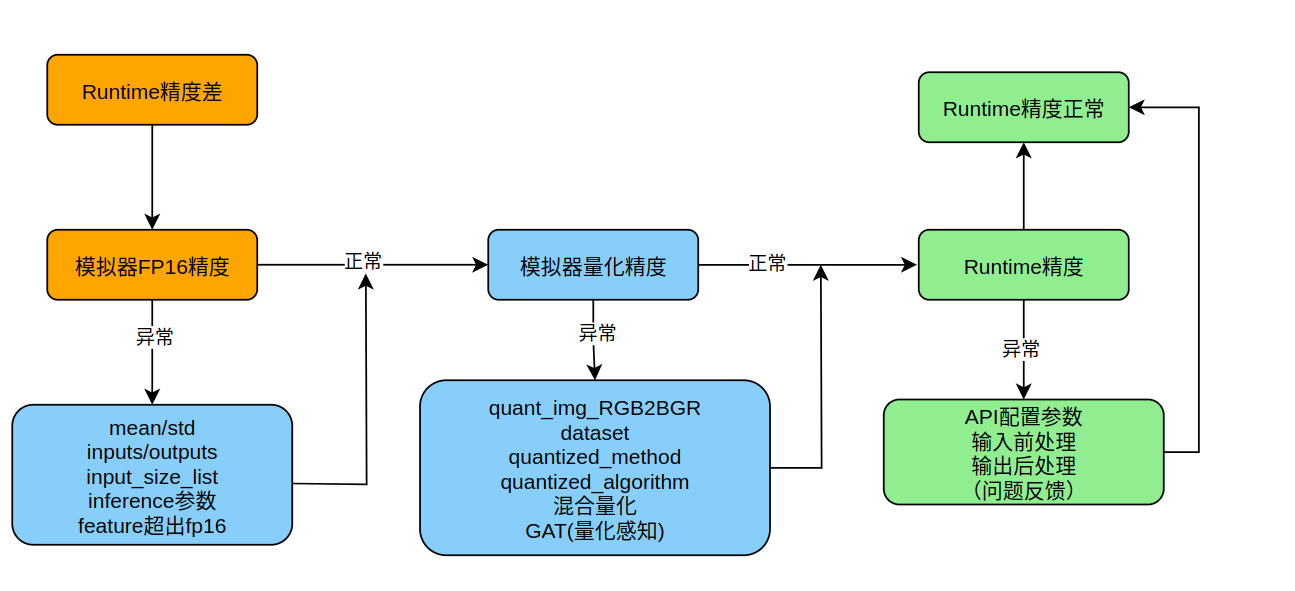
-
层级性能分析:在板端使用
vpm_run命令执行模型时,附加-cnnprofile_level 2参数,即可获取每一层的详细性能分析报告。